A Odisséia de Observabilidade de Sofia: Nada Está Quebrado. Esse é o Problema.
Vinte máquinas críticas de validação de cartões monitoradas por um script de ping no Telegram — Sofia e Lauren ligam a luz com Node Exporter e Netdata e descobrem que estabilidade sem margem é só uma contagem regressiva.

As máquinas estão super de boa, estáveis, mas ainda sim são beeem críticas e super importantes para a nossa jornada de validação de cartões. São Windows e Linux. Raramente dão problema, temos um alerta que chega no celular e funciona top demais.
— Foi o que o Josias disse. Cê acredita que eles recebem notificação no celular, pelo Telegram, por um script? Cada vez que uma máquina dá problema, se o serviço cai, é "ping", se volta, é "pong" — contou Sofia.

Lauren arregalou os olhos.
— Mano do céu… isso me dá até coceira. E você e a Luana responderam o quê?
Sofia suspirou.
— Eu queria ter me fingido de sonsa, mas a Luana, como toda boa gerente de produto, fez o que precisava ser feito: vai para o backlog, com prioridade. Perguntei quando eles vão se livrar dessas máquinas migrando para a nuvem… prazo estimado: dois anos.
— DOIS ANOS!!? Eles querem que a gente faça o quê? Crie um cercadinho em volta e deixe tudo em quarentena?
Sofia estendeu um chiclete.
— Pois é. Mas até lá, precisamos colocar essas máquinas no mapa. Pulverizar Node Exporter em tudo resolve?
Lauren inclinou a cabeça.
— Por mim, sim, é simples e efetivo. Sem firula. Mas e a burocracia? Acesso, firewall, credencial, janelas de mudança e etc?
— Uma semana, pelo menos — respondeu Sofia. — Mas já dá para apresentar um desenho ao time de cartões e diminuir a ansiedade deles.
— Faz o diagrama por favor e me mostra antes de apresentar ao Josias e o time dele. Diz Lauren.
Vamos explicar como funciona a coleta de dados a partir de agente instalado em servidores.
Como funciona o envio de dados de telemetria a partir de um agente instalado em um servidor?
Abaixo temos um simples desenho sobre como isso funciona utilizando o vmagent (Victoria Metrics), uma alternativa ao node_exporter.
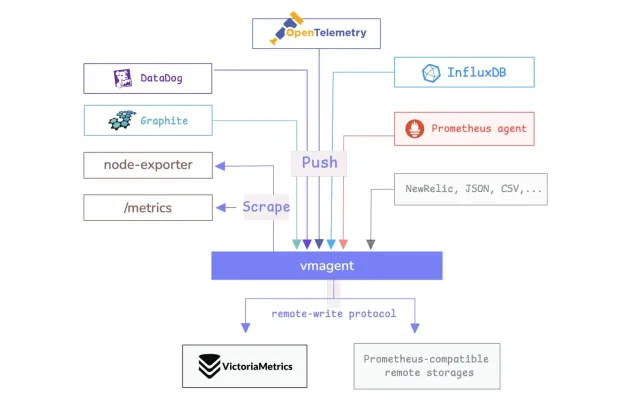
O vmagent pode tanto receber dados quanto fazer a coleta por conta própria, dessa forma, ele cobre os dois cenários mais comuns, onde serviços expõem dados para serem coletados ou realizam o envio para o agente. Prático, não?
Como ficou o diagrama da Sofia?
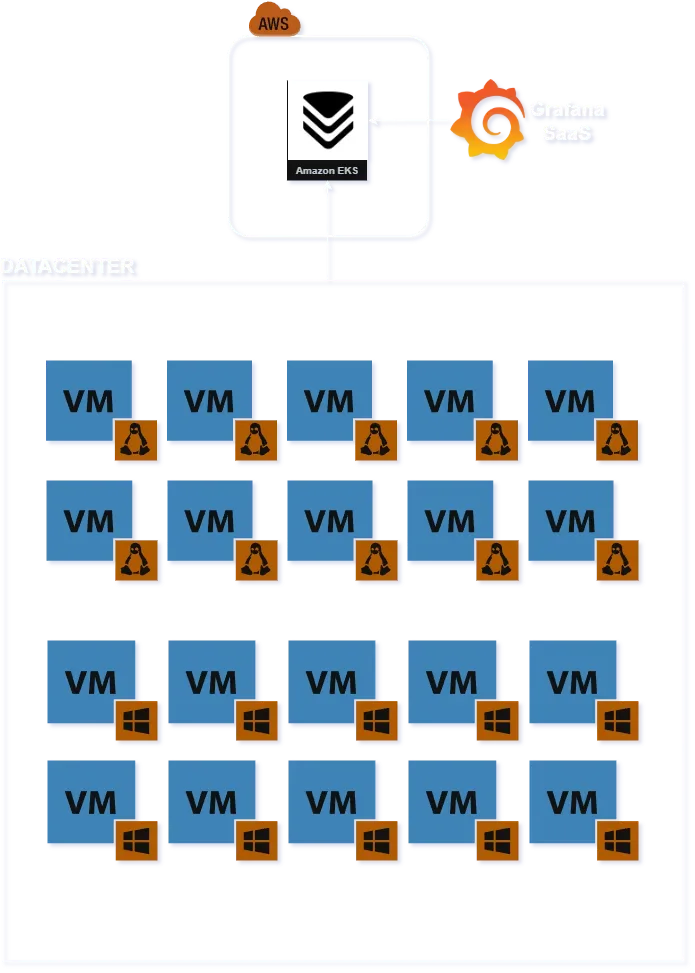
Descrição:
- Modelo híbrido (On-Prem → Cloud).
- Coleta descentralizada (agent-based).
- Armazenamento centralizado em Kubernetes.
- Visualização externalizada via SaaS.
- Stack inteira compatível com ecossistema Prometheus.
— E aí, o que achou? — perguntou, girando o notebook para Lauren.
— Você datilografou esse desenho? — Lauren disse, com o sorriso debochado de sempre.
— Não amola. Vai servir. Vou validar com o Josias e entender melhor o ambiente.
Sofia ficou alguns segundos olhando para o diagrama.
— Minha preocupação não é instalar agente. É comportamento. Tenho a sensação de que, quando a gente ligar a luz ali dentro, vai aparecer coisa que ninguém quer ver.
Lauren riu.
— Não duvido de nada. Vamos começar por amostragem. Duas máquinas Linux, duas Windows. Se tudo ficar estável, replicamos. Mas o mais interessante vai ser observar durante a execução dos batchs.
Sofia fez uma careta.
— Analisar IO de disco às duas da manhã. Meu tipo favorito de diversão.
— A janela de mudança é na madrugada, né?
— Claro que é — respondeu Sofia, levantando-se da mesa.
Lauren ficou em silêncio por um instante, pensando.
— Espera. A gente pode deixar o Netdata rodando temporariamente nas máquinas. Ele coleta tudo em alta resolução. De manhã analisamos o histórico completo.
Sofia cruzou os braços.
— E o overhead? CPU, memória, disco… essas máquinas não são exatamente jovens.
— Vamos rodar por poucas horas. Ele faz um raio-x detalhado e a gente remove depois. Se tiver algo escondido, aparece.
Sofia olhou novamente para o desenho na tela. Não era sobre ferramentas. Era sobre visibilidade real.
— Então tá. Vamos ligar a luz.

Uma semana depois, às 8 horas da manhã no escritório após a madrugada de execução dos batchs da estrutura de cartões, o escritório cheirava a café enquanto elas olhavam atenciosas ao monitor do notebook.
— CPU verde, memória verde, nada perto de 100%. Lauren girou a cadeira para o lado de Sofia. — Viu? Era só colocar no mapa. Estão saudáveis.
Sofia não respondeu de imediato. Ajustou o filtro de horário no dashboard para a janela da liquidação noturna, entre 01:00 e 03:30. A CPU continuava comportada. Mas o gráfico de I/O contava outra história.
— Olha isso aqui.
A linha de iowait subia silenciosa durante o processamento batch. Não explodia. Não passava de 20%. Mas permanecia elevada por quase duas horas. Ao lado, a latência média de escrita dobrava no mesmo período. No Windows, a Disk Queue Length fazia o mesmo movimento, como um reflexo imperfeito.
Lauren se inclinou para frente. — Não chega a estourar nada, mas...
— Mas não precisa estourar — respondeu Sofia, abrindo outro painel. — Olha o tempo médio dos jobs.
Ela sobrepôs os dados de processamento dos últimos três meses que o time de cartões havia guardado. O batch principal, responsável por validar cartões antes da liquidação, vinha aumentando a cada ciclo. Nada alarmante isoladamente. Mas a curva era constante.
— Eles estão processando mais volume por causa da campanha — disse Lauren, já menos segura.
— Sim. E o disco está acompanhando no limite.
Sofia ampliou o gráfico de uso de espaço. 78%. Crescimento linear. Sem política clara de retenção.
A sala ficou silenciosa por alguns segundos.
— Então o que você está dizendo? — Lauren perguntou.
Sofia cruzou os braços, encarando a tela.
— Estou dizendo que não temos falha. Temos margem zero. E margem zero em sistema de pagamento não é estabilidade. É contagem regressiva.
Lauren respirou fundo.
— Ou seja… o "ping" nunca mentiu. Ele só nunca contou a história inteira.
Sofia assentiu.
— Exato. A máquina só avisa quando cai. A gente precisava ouvir quando ela começa a cansar.
Lauren fechou o notebook devagar.
— Então não é sobre modernizar por hype. É sobre sobreviver até modernizar.
Sofia deu um meio sorriso.
— É sobre não deixar a sorte virar estratégia.
Após a apresentação do relatório ao time de cartões, a migração para a nuvem ganhou a velocidade e a seriedade que merecia. Nenhum alerta disparou. Nenhum "ping" ecoou no Telegram. Naquele dia, nenhuma máquina caiu. O script do "ping" e do "pong" continuou orgulhoso da própria simplicidade. Mas algo havia mudado. As vinte máquinas deixaram de ser caixas estáveis em um datacenter distante e passaram a ser sistemas com tendência, limite e risco mensurável. Não houve revolução arquitetural. Não houve heroísmo. Houve baseline. Houve margem calculada. Houve decisão consciente. E, para uma operação que valida cartões enquanto o resto do mundo dorme, isso vale mais do que qualquer alerta vermelho às três da manhã.
Glossário:
- Disk Queue Length: É o número médio de operações de leitura e gravação pendentes na fila de um disco durante um intervalo de tempo específico, indicando possível sobrecarga quando valores altos persistem.
- iowait: É a porcentagem de tempo que a CPU fica ociosa aguardando a conclusão de operações de entrada/saída (E/S), como leituras ou gravações em disco.
- Node Exporter: É um agente de monitoramento open-source do ecossistema Prometheus, projetado para coletar e expor métricas detalhadas de nível de sistema em hosts Linux/Unix, como uso de CPU, memória, I/O de disco, rede e estatísticas de kernel.
- Netdata: É uma plataforma de monitoramento em tempo real para servidores, containers e aplicações, que coleta métricas automaticamente e mostra tudo em dashboards com alertas.
- vmagent: O vmagent é um agente leve do VictoriaMetrics projetado para coletar métricas de diversas fontes. Ele permite relabeling, filtragem, agregação e deduplicação de dados antes de enviá-los para storages compatíveis via protocolo remote_write do Prometheus ou do próprio VictoriaMetrics.
O que é "A Odisséia de Observabilidade de Sofia"?
Adso Castro escreve sobre Observabilidade e SRE contando histórias pessoais e não tão pessoais assim, utilizando personagens fictícios na trama. A ideia é abordar assuntos complexos do mundo de Cloud Native de uma forma mais amigável. As histórias giram em torno das personagens Sofia e sua amiga e colega de equipe, Lauren.

