A Odisséia de Observabilidade de Sofia: Victoria Metrics e a escala da observabilidade
Prometheus batendo OOM de 4 em 4 horas e a retenção precisando ir de uma semana para um mês — Sofia descobre o Victoria Metrics, explica RED & USE com uma barraquinha de pastel e corta o consumo de memória pela metade.

Anteriormente em A Odisséia de Observabilidade de Sofia:
Em uma agitada empresa de tecnologia financeira, a Engenheira de Confiabilidade de Site, Sofia Wang, enfrentou o caos de alertas avassaladores, liderando sua equipe em direção a uma abordagem mais eficiente. Ela então se aventurou na enigmática floresta de logs, domando a bagunça de logs não estruturados por meio de práticas padronizadas. Agora, Sofia confronta as limitações do Prometheus, embarcando em uma nova aventura em busca do armazenamento de métricas a longo prazo perfeito. Com sua paixão pela telemetria, Sofia busca liberar o poder do Victoria Metrics e fortalecer sua infraestrutura de monitoramento. Será que a jornada incansável de Sofia pela observabilidade levará a insights incomparáveis? Cola aí e vem testemunhar o próximo capítulo emocionante na notável jornada de Sofia.
- "Out of memory de novo? Não deu nem 4 horas desde o último restart desse workload... mano do céu". Diz a jovem SRE enquanto olha para o monitor pensativa.
A implantação simples do Prometheus rodando em Kubernetes, anteriormente uma espinha dorsal eficiente, começou a mostrar sinais de tensão sob a avalanche de coleta de dados. Os desafios enfrentados por Sofia ecoavam as lutas de Sophie para compreender teorias filosóficas complexas. A tarefa em questão era assustadora, mas clara: ampliar o período de retenção das métricas de uma semana para um mês inteiro.
Sofia destrinchou tudo o que encontrara sobre performance de Prometheus. Aplicou o máximo de filtros e relabels que pode. Subiu um Prometheus isolado para coletar métricas de específicos pontos do cluster. Ainda sim, sem sucesso. Tinha muita métrica chegando. Os pods estavam batendo OOM em questão de horas.

Buscando uma solução, Sofia descobriu o Victoria Metrics. Com sua profunda capacidade de lidar com grandes volumes de dados de métricas e estender o período de retenção de dados, o Victoria Metrics apresentava uma chave promissora para desvendar os mistérios de sua infraestrutura de monitoramento.
-
Peraí... como assim eu descobri? Pergunta Sofia indignada.
-
Uai, você estudou, pesquisou, até encontrar essa solução... não?
-
Antes fosse simples assim. Deixa eu contar como foi.
-
Por favor...
-
Eu sou inscrita na lista de emails do Prometheus. Interagi com a comunidade algumas vezes e certa vez, o CEO/Fundador do Victoria Metrics respondeu uma dúvida minha sobre performance e fiquei assustada. Achei que era um maluco tentando vender um produto aleatório. Foi quando fui pesquisar sobre e vi que era uma ferramenta concorrente do Prometheus. Mas foi quando um amigo engenheiro de software, Miltinho, que trampa em outra empresa me mandou uma mensagem uma vez que estavam fazendo uma PoC com o Victoria Metrics. Apesar de eu estar lendo e assistindo coisas sobre o Thanos e também o Cortex, o maior problema era a curva de aprendizado. Eu não estava afim de subir uma solução complexa para esse problema e virar mãe do sistema, como acontece em muitos lugares o tempo todo. Quando ele me disse que o Victoria era relativamente mais simples que os concorrentes e muito eficiente, me deixou empolgada e testei assim que pude.
Victoria Metrics
![]()
- Então eu achei um vídeo da PromCon 2019, onde Alejandro Vicente da ADIDAS fez uma apresentação sobre o VM chamada "Remote Write Storage Wars". Cara, os números eram absurdos. O serviço é tão otimizado que batia os números de todos os concorrentes. Se liga na imagem abaixo:
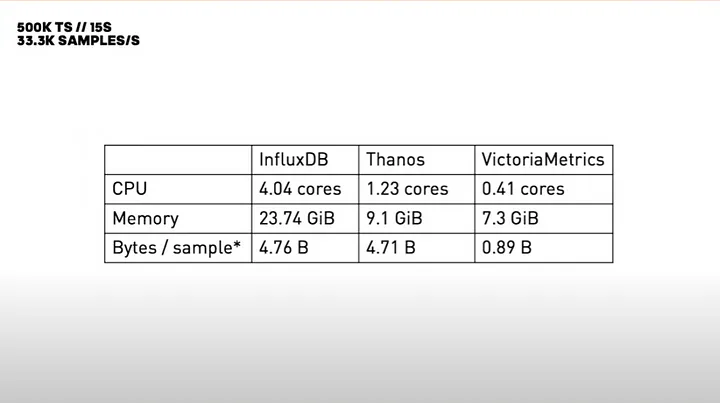
-
Viu? Serviço é sinistro. Diz a moça impressionada.
-
Entendi, agora faz sentido, posso continuar com o artigo?
-
Vai vai...
Bom, voltando, Sofia percebeu que o Victoria Metrics era de fato, uma solução para seus problemas. Porém, os desenvolvedores precisavam de uma orientação quanto ao processo de instrumentação de aplicações com métricas. Algo precisava ficar claro pra galera. Assim, ela os introduziu ao conceito de RED & USE.
Vamos usar o exemplo de uma barraquinha de pastel.

RED (Rate, Erros, Duration):
Imagine que você está administrando uma barraca de pastéis.
- Rate: Isso é quantos pastéis você vende por hora. Se você vender 10 pastéis em uma hora, sua taxa é de 10 pastéis por hora.
- Erros: Isso é quantas vezes algo dá errado. Talvez você derrube um pastel, ou talvez dê o troco errado. Se você cometer 2 erros em uma hora, sua taxa de erro é de 2 por hora.
- Duration: Isso é quanto tempo você leva para servir um cliente. Se levar 5 minutos para preparar um pastel, receber o pagamento e dar o troco, sua duração é de 5 minutos.
USE (Utilização, Saturação, Erros):
Agora, vamos imaginar que você não está apenas vendendo os pastéis, mas também os preparando.
- Utilization: Isso é quanto do tempo você está ocupado preparando pastéis. Se você passar metade do tempo preparando pastéis e metade do tempo esperando clientes, sua utilização é de 50%.
- Saturation: Isso é quantos clientes estão esperando enquanto você está ocupado. Se tiver 3 clientes esperando toda vez que você estiver preparando pastéis, sua saturação é de 3.
- Erros: Isso é quantas vezes algo dá errado ao preparar os pastéis. Talvez você coloque muito recheio, ou talvez esqueça os ingredientes principais. Se você cometer 1 erro a cada hora, sua taxa de erro é de 1 por hora.
Em outras palavras, RED ajuda você a entender o quão bem está vendendo os pastéis, e USE ajuda você a entender o quão bem está preparando os pastéis.
Com o time de desenvolvedores na mesma página quanto ao que precisa ser metrificado, Sofia pode dar andamento na arquitetura do Victoria Metrics.
O serviço possui duas versões, Single e Cluster. A primeira é uma versão simples: um único serviço faz todo o processo que o Prometheus faz. Coleta, recebe, armazena e serve métricas. Porém, a parte de escala é perdida, sendo possível apenas escalar verticalmente, injetando mais recursos na instalação.
Já a versão Cluster possui escala de todas as formas, vertical e horizontalmente, pois ela quebra os componentes da versão Single em múltiplos serviços. Vejamos a imagem abaixo:
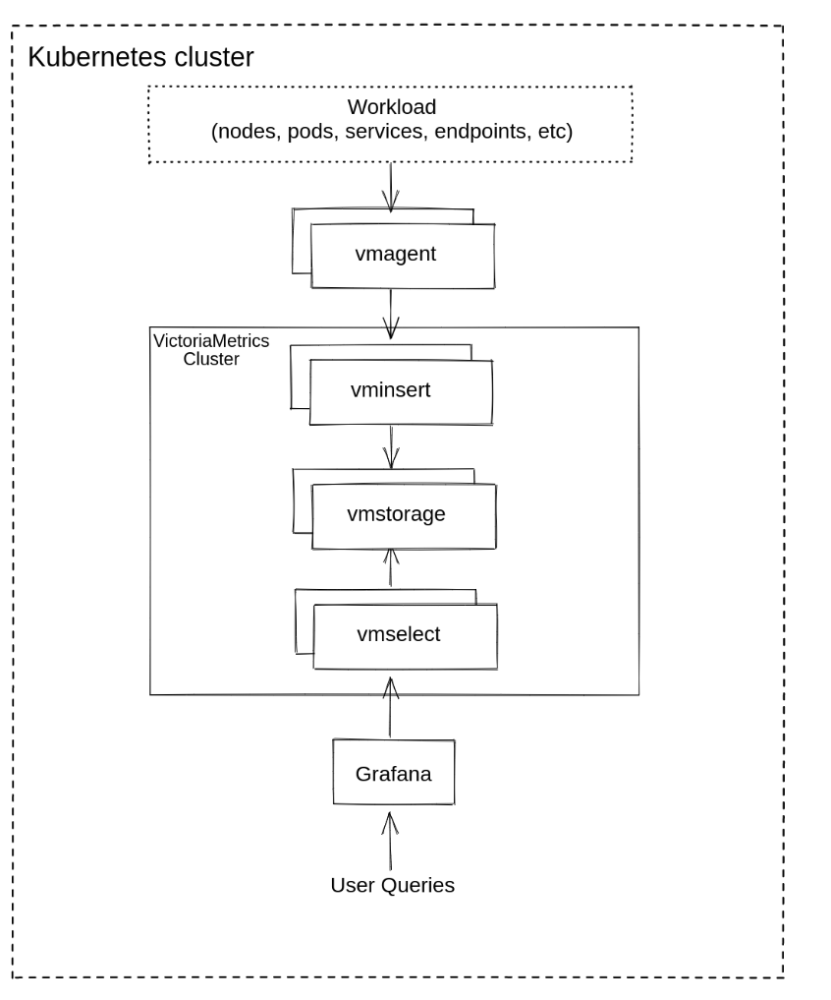
VM Agent:
É o serviço que faz a coleta das métricas. Pense nele como um Prometheus com esteróides e sem a parte de server do serviço, possuindo apenas as ferramentas para fazer coleta e repasse de dados. É por isso que ele é absurdamente eficiente e, principalmente, leve.
VM Insert:
É o serviço que faz a recepção das métricas, distribuindo-as entre os nodes de vmstorage por nomes de métricas e labels.
VM Select:
É o serviço que roda queries nos vmstorages e as fornece ao endpoint que as solicita, como por exemplo, Grafana.
VM Storage:
Guarda as métricas em disco.
Com essa arquitetura em mente, Sofia se assustou com a quantidade de recursos que economizou substituindo todos os Prometheus que atendiam partes específicas do cluster de Kubernetes por um simples vmagent. Ela deixou um vmagent coletando métricas de cada aplicação que rodava no cluster, todos estes reportando a uma instalação centralizada de Victoria Metrics, com os demais componentes configurados.
Bingo. Estabilidade. Economia de recursos. Tudo estava bem e ia bem nesse novo cenário.
-
"Nem fod(*#¨do... o consumo de memória de toda instalação caiu em 50%... que magia é essa? Pergunta para si mesma a moça confusa. Alou? Miltinho? Cara, ce acredita que o consumo de recurso caiu em 50%, pelo menos?" Sofia diz ao colega de faculdade pelo telefone ainda assustada.
-
"Caraca, sério?" Respode Milton, colega de Sofia. "Te falei, os caras escovam bit, só pode".
-
"Assim, não sei se o Thanos ou mesmo o Cortex seriam mais confiáveis a nível de estabilidade e teriam esse nível de performance, mas cara, que absurdo." Ela reflete.
-
"Duvido muito, assim, o Thanos é muito bom e bem sólido na comunidade CNCF, mas pra um ambiente mais simples acho desnecessário." diz Milton. "Sem falar na cur..."
-
"Curva de aprendizado" Interrompe Sofia. "Sim, to ligada, a galera aqui ia levar um certo tempo pra aprender como funciona e dar manutenção. De qualquer forma, obrigada viu?"
-
"Sem crise, que bom que funcionou, vou levar como feedback pra galera aqui e seguir nossa PoC, nossa stack de Prometheus tá indo ao espaço já de tão vertical kkkkk". Diz Milton dando risada.
-
"Haha, boa sorte" responde ela encerrando a ligação.

E assim, o problema de escala de métricas estava resolvido. Sofia entendeu que sua dedicação na resolução desse problema não foi em vão. Fazendo esse retrospecto, ela percebeu que não se tratava de encontrar a solução mais perfeita possível, mas sim, uma que de fato resolvesse o problema de forma eficiente.
O que é "A Odisséia de Observabilidade de Sofia"?
Adso Castro escreve sobre Observabilidade e SRE contando histórias pessoais e não tão pessoais assim, utilizando personagens fictícios na trama. A ideia é abordar assuntos complexos do mundo de Cloud Native de uma forma mais amigável. As histórias giram em torno das personagens Sofia e sua amiga e colega de equipe, Lauren.

